Part 1.
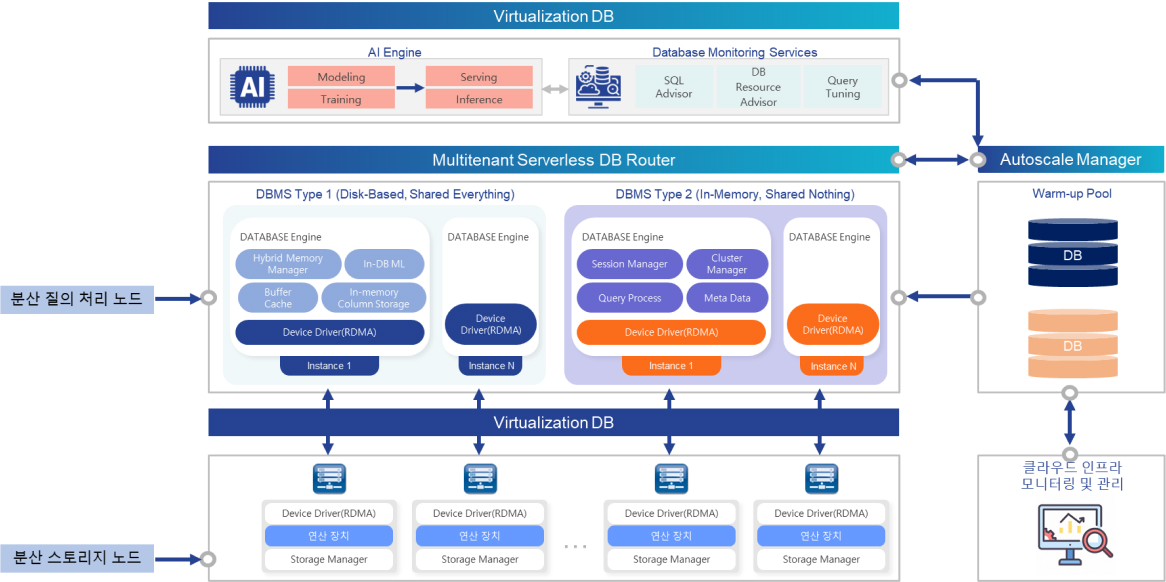
스토리지 분리 환경에 적합한 샤딩 기반 분산 DBMS 기술, 데이터 접근 최적화 기술, 임시데이터 저장 및 관리 기술
스토리지 분리 (Disaggregated Storage) 환경에서 데이터 접근 최적화
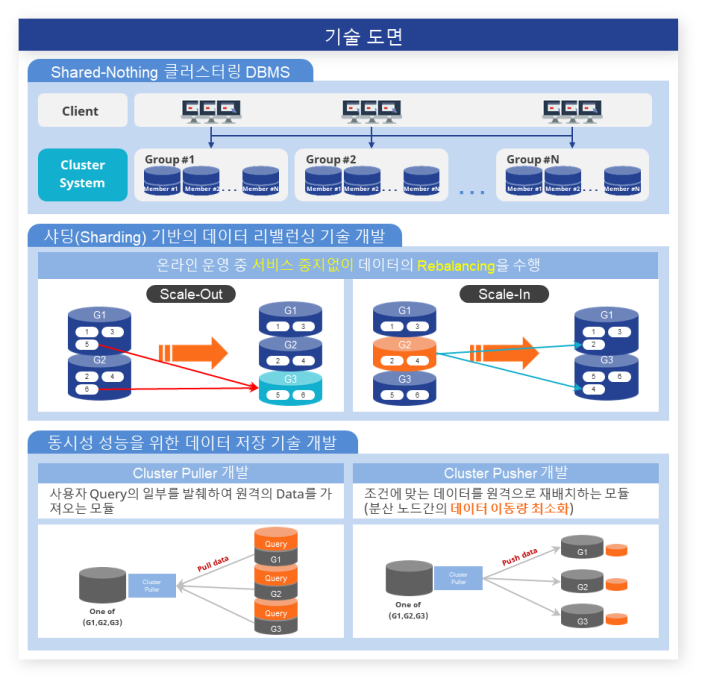
NoSQL의 수평적 확장성(Scale-Out) 장점과 기존 RDBMS SQL 및 ACID 장점을 모두 제공하기 위해,
샤딩(Sharding) 기반 분산 DBMS 기술 및 관련 요소 기술
임시 데이터(Ephemeral Data) 저장 및 관리 기술
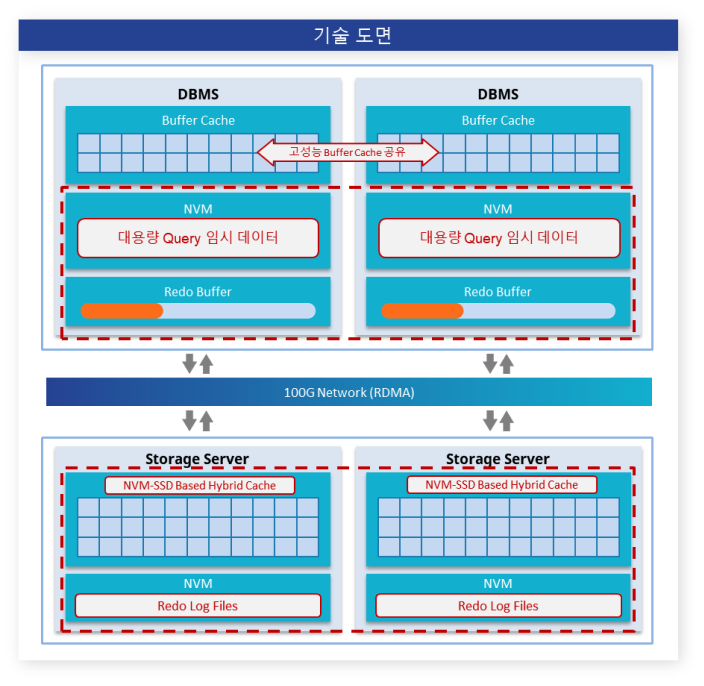
고성능 하드웨어 클라우드 환경에 최적화된 OLTP 데이터베이스 기술
NVM, RDMA, NVMeOF, 100GB 네트워크 스위치 등 고성능 HW 기반 분산 데이터베이스 신뢰성, 가용성, 동시성 제어, 성능 향상 기술
네트워크 쓰기 트래픽 및 지연 최소화를 통한 차세대 복제 (Replica) 관리 기술
비휘발성메모리 도입에 따른 딥-메모리계층구조에서 최적 데이터 Placement 및 캐싱 기술
OLTP 데이터베이스 AI 기반 최적화 기술 (예: 인덱싱, 버퍼관리, 질의 최적화, 실시간 튜닝 등)
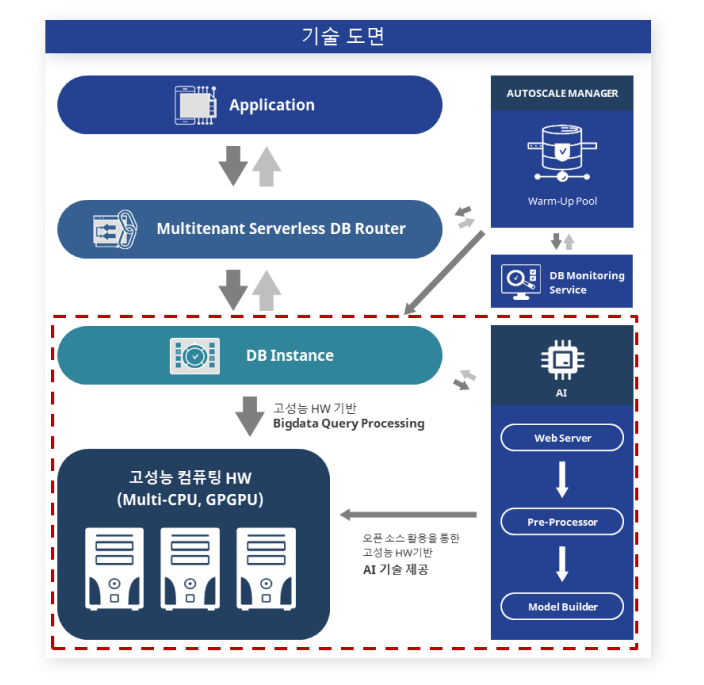
차세대 컴퓨팅 자원 기반의 빅데이터 및 AI 처리 데이터베이스 기술
멀티코어 CPU, GPGPU 융합을 통한 빅데이터 및 AI 처리 가속화 기술
서버리스(Serverless) 환경에서 Auto-Scaling 및 저지연 콜드스타트(Cold Start) 기술
대용량 임시 데이터에 대한, 고성능 HW기반의 효과적인 분산 저장, 관리 기술
분석질의처리 가속을 위한 Column 기반 저장과 압축 기술
DB 엔진에서 ML 응용의 직접 지원 (즉,In-Database ML)을 위해 SQL 확장 및 처리 최적화 기술
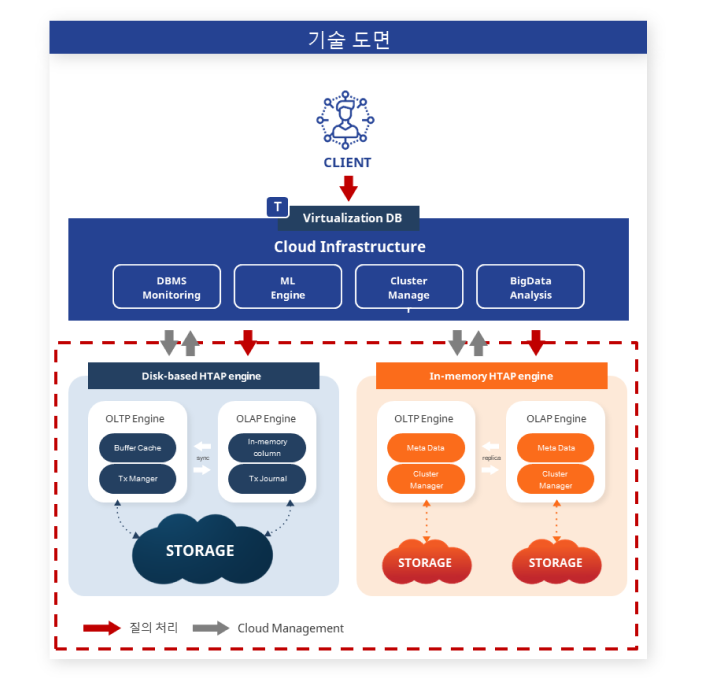
OTLP 및 OLAP를 통합한 HTAP 지원 기술
클라우드向 고성능 HTAP 지원을 위한 데이터베이스 최적화 기술
ML 기술 적용을 통한 HTAP 데이터베이스 최적화 기술
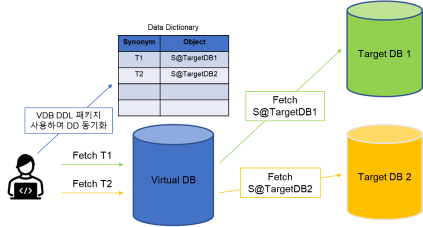
Virtual Database Package를 이용한 통합 기술
Remote DBMS에 Data를 생성, 조회, 삭제, 변경 할 수 있도록 해주는 패키지 제공
DDL을 Remote DBMS에 수행하고 Virtual DBMS의 Data Dictionary에 저장하는 기능 제공
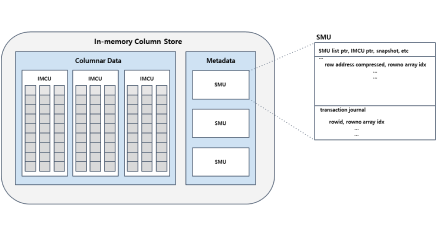
HTAP 환경에서 Column 단위의 분석형 질의를 빠르게 처리하기 위한 Column 기반 데이터 저장, 처리 기술
Row 기반 데이터를 Column 기반 데이터 포맷으로 만들어 In-memory로 저장하는 기술
메모리 효율을 높이기 위한 Column 기반 데이터를 압축하는 기술
Row 기반 데이터와의 정합성 유지 및 데이터 최신화를 위한 Transaction Journal 기술
Scan 효율을 높이기 위한 불필요한 데이터를 Pruning 하는 기술과 SIMD Vector 연산을 통한
Filter 처리 기술
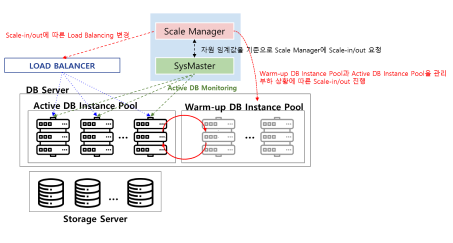
현재 워크로드 상황에 따른 DB 인스턴스 Auto-scale In/Out 기술
Warm-up 된 DB 인스턴스 풀 관리를 통한 Auto-scale In/Out 기술
워크로드 모니터링을 통한 데이터베이스 간 Load Balancing 기술
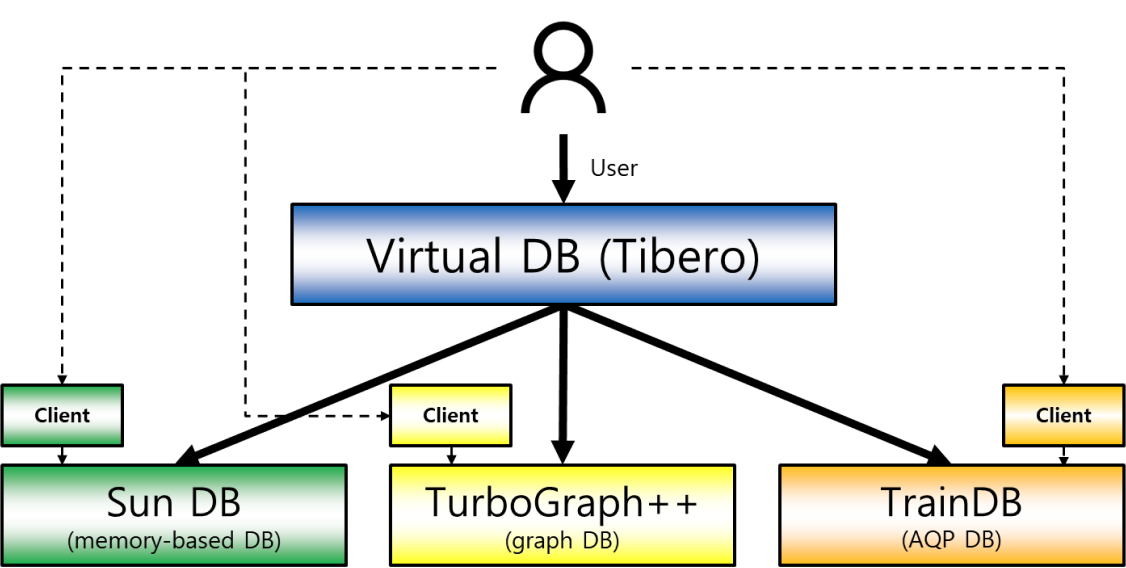
빅데이터 분석 및 AI 처리를 위한 클라우드向 차세대 DBMS 시스템을 포괄하는 데이터베이스
Virtual DB는 과제 내의 모든 DB와 연동되어 있으며 User는 Virtual DB를 통해 모든 DB에 접근할 수 있음
Virtual DB와의 연동을 위해 각 DB는 JDBC 표준을 지원하여야 함
Virtual DB로는 Tibero를 사용함
Viirtual DB(Tibero) 와 In-memory based DB(SunDB)는 DBLink로 연결함
SunDB 외에 AQP DB, GraphDB 등 연동 예정임
VDB 내용이 반영된 tibero 7 바이너리 다운로드
예) tibero7-bin-VDB.tar.gz 다운로드
바이너리 압축 해제
gunzip tibero7-bin-VDB.tar.gz
tar xvf tibero7-bin-VDB.tar
환경설정
압축을 푼 tibero 디렉토리에서 .profile 생성
발급받은 license.xml 파일을 복사
i. cp license.xml $TB_HOME/license/
gen_tip.sh 수행하여 초기파라미터 관련 파일들 생성
i. sh $TB_HOME/config/gen_tip.sh
포트 설정
i. vi $TB_HOME/config/tibero.tip
ii. vi $TB_HOME/client/config/tbdsn.tbr
iii. 위의 두 파일에서 LISTENER_PORT의 번호를 변경 (default: 8629)
자동 스크립트 사용하여 빌드 및 설치, 구동
i. cd $TB_HOME/bin
ii. sh tb_create_db.sh
구축 완료 후 tbsql 수행
docker 설치
ubuntu 20.04 이미지 설치
이미지 이름 확인
컨테이너 생성
컨테이너 구동 확인
안 켜져 있으면, sudo docker start [컨테이너 이름]
컨테이너 정상 구동 확인
컨테이너에 unzip, vim, JAVA 등이 설치
시스템 변수
iii. vim /etc/security/limits.conf 후 다음 맨 밑에 추가
Goldilocks 설치
다음은 docker 가 아닌 터미널에서 수행
아래 링크에서 goldilocks 다운로드
다운로드 된 폴더에서 sudo cp goldilocks-server-20c.20.1.26-linux-x86_64.tar.gz
/goldilocks/goldilocks-server-20c.20.1.26-linux-x86_64.tar.gz
cd /goldilocks
sudo tar -xvzf goldilocks-server-20c.20.1.26-linux-x86_64.tar.gz -C /goldilocks/gold
환경 변수 설정
다음은 docker에서 수행
vim ~/.bashrc 후 다음 맨 밑에 추가 후 source ~/.bashrc
License 발급
license 파일이 없는 경우, startup 시에 에러가 발생하기 때문에, 선재소프트 담당 연구원님께 데모 라이센스를 요청해야 한다.
라이센스 발급을 위해 필요한 정보는 다음과 같다. (docker container 안에서 수행)
받은 라이센스 파일은 $GOLDILOCKS_HOME/license 에 복사
받은 라이선스 파일 이름은 license로 만든다.
DB 생성 및 구동
DB 생성
라이센스 발급을 위해 필요한 정보는 다음과 같다. (docker container 안에서 수행)
DB 구동
Database schema 정보 구축
gsql --as sysdba --import $GOLDILOCKS_HOME/admin/standalone/DictionarySchema.sql
gsql --as sysdba --import $GOLDILOCKS_HOME/admin/standalone/InformationSchema.sql
gsql --as sysdba --import $GOLDILOCKS_HOME/admin/standalone/PerformanceViewSchema.sql
Listener 구동
리스너를 따로 켜야만 원격으로 DB에 접속 가능하기 때문에 DBLink를 위해서는 필수적으로 리스너를 실행해야 한다.
리스너 on/off는 다음과 같이 할 수 있다.
Database 삭제
혹시라도 DB 설치를 잘못한 경우, 이를 삭제하고 다시 설치해야 한다.
rm -rf $GOLDILOCKS_DATA/db/*.dbf
rm -rf $GOLDILOCKS_DATA/wal/*.ctl
rm -rf $GOLDILOCKS_DATA/wal/*.log
rm -rf $GOLDILOCKS_DATA/archive_log/*.log
Data 테이블스페이스 생성
CREATE TABLESPACE [테이블스페이스 명] DATAFILE [데이터파일 명] SIZE [크기];
데이터 파일 추가
ALTER TABLESPACE [테이블스페이스 명] ADD DATAFILE [데이터파일 명] SIZE [크기];
TEMP 테이블 스페이스 생성
CREATE TEMPORARY TABLESPACE [테이블스페이스 명] MEMORY [데이터파일 명] SIZE [크기];
데이터 파일 추가
ALTER TABLESPACE [테이블스페이스 명] ADD MEMORY [데이터파일 명] SIZE [크기];
유저 생성
CREATE USER user_identifier IDENTIFIED BY password [ DEFAULT TABLESPACE tablespace_name ]
[ TEMPORARY TABLESPACE tablespace_name ] [ INDEX TABLESPACE tablespace_name ]
유저 권한 설정
GRANT ALL ON DATABASE TO [username];
로그인 확인
session 접속 시도
쿼리 수행 여부 확인
Java Gateway 설정
$TB_HOME/client/bin 의 tbJavaGW.zip 압축 해제
$TB_HOME/client/bin/tbJavaGW/lib에 goldlocks JDBC 추가
$TB_HOME/client/bin/tbJavaGW/jgw.cfg 수정
$TB_HOME/client/bin/tbJavaGW/tbgw 수정
$TB_HOME/client/bin/tbJavaGW 에서 ./tbgw 수행
Java EPA 설정
$TB_HOME/config/$TB_SID.tip 파일에 아래 설정 추가 (보통 tibero.tip 파일)
$TB_HOME/client/config/tbdsn.tbr 파일에 아래 추가
$TB_HOME/client/epa/java/lib/goldilocks6.jar 파일 추가
$TB_HOME/client/bin/tbjavaepa 파일 수정
Tibero 설정
create_vdb.sql, pkg_vdb_goldilocks.sql, _pkg_vdb_goldilocks.sql 스크립트를 sys계정으로 수행
TEST
goldilocks ip, goldilocks port, goldilocks id, goldilocks password 순서로 인자를 준다.
goldilocks ip는 docker 에서 hostname -I 로 확인한다.
exec VDB_GOLDILOCKS.REGISTER_CONNECTION_INFO('192.1.3.81', '22581', 'sys', 'gliese’);
동작 확인
접속 정보 오기입시 아래 함수 호출 후 VDB_GOLDILOCKS.REGISTER_CONNECTION_INFO 재수행
실패시 tbsql 안에서 drop java source "EXECUTE_DDL_JDBC";
@$TB_HOME/scripts/create_vdb.sql 재수행
VDB_GOLDILOCKS 패키지
Tibero 에서 remote DB(Goldilocks DB) 로의 DDL 수행 및 remote DB의 object 관리를 위한 패키지
패키지에서 제공하는 함수
REGISTER_CONNECTION_INFO
Goldilocks DB에 접속하여 DDL을 수행하기 위한 정보를 등록하는 함수
Parameters
스펙
Exec vdb_goldilocks.register_connection_info(‘192.1.3.22’, ‘22581’, ‘u1’, ‘u1’);
UNREGISTER_CONNECTION_INFO
등록된 connection info를 제거하는 함수
Parameters
스펙
Exec vdb_goldilocks.unregister_connection_info();
EXECUTE_DDL
VDB를 통해 Goldilocks DB에 DDL을 수행하기 위한 함수
Parameters
스펙
Exec vdb_goldilocks.execute_ddl(‘create table t1 (a number)’);
REGISTER_OBJECT
사용자가 VDB를 통하지 않고 Goldilocks DB에 직접 접속하여 object를 생성할 수 있는데, 이런 경우에는 VDB에서 관리할 수 없다.
이 때 register_object 함수를 사용하여 VDB에 object를 등록할 수 있다.
Parameters
스펙
Exec vdb_goldilocks.register_object(‘U1’, ‘T1’);
UNREGISTER_OBJECT
사용자가 더 이상 VDB에서 Goldilocks object를 사용하지 않을 때, unregister_object 함수를 통해 VDB에 등록되어 있는 object를 제거할 수 있다.
Parameters
스펙
Exec vdb_goldilocks.unregister_object(‘U1’, ‘T1’);
워크로드 증감에 따른 DB 인스턴스 Auto Scale-in/out
Warm-up된 DB 인스턴스 풀 관리를 통한 신속한 Auto Scale-in/out
워크로드 모니터링을 통한 DB 인스턴스 간 Load Balancing
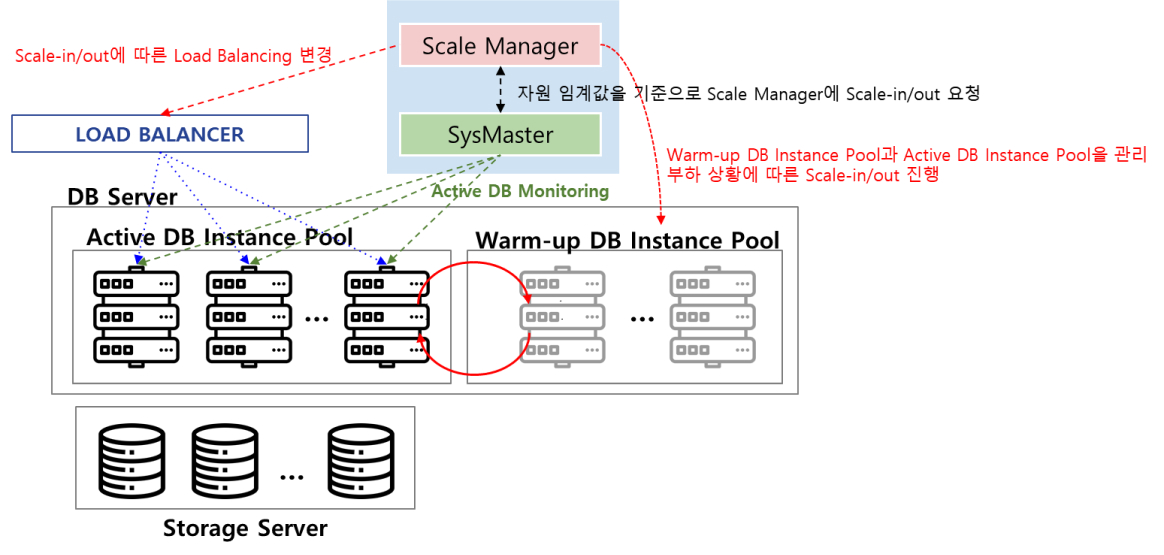
ScaleManager(Pod에 Instance Pool에 속할 DB 설정 및 Pod 정보 확인)
각 Pod별 티베로 환경설정 및 티베로 설치(TAC)
k8s Master or 하나의 Pod에 Sysmaster 및 ScaleManager 관련 환경설정 및 설치
ScaleManager 기동 및 Sysmaster 기동
ScaleManager(환경 구성 및 Instance Pool 등록)
pod별 podname, pod ip 등 확인
Instance Pool에 DB 등록
ScaleManager(Instance Pool 모니터링 시작)
DB Instance Group화 및 DB Monitoring 시작
모니터링 대상 상황 및 관제 내용 Sysmaster/kubectl을 통한 확인
SQL문을 통한 DBMS 내에서의 ML 기능 제공 : 데이터 과학자 없이 DBA 인력만으로 모델의 학습/추론과 같은 고성능 머신러닝 기능의 사용
데이터베이스 내 고성능 모델 제공 : 주어진 과제에 맞는 기생성 / 학습된 모델을 통해 즉시 학습과 추론할 수 있도록 제공
티베로 데이터베이스 내의 데이터를 대상으로 한 대규모 학습 기능 제공 : DBMS 내에서 대규모 데이터베이스를 대상으로 데이터 탐색, 변환, 분석 및 추론 기능 제공
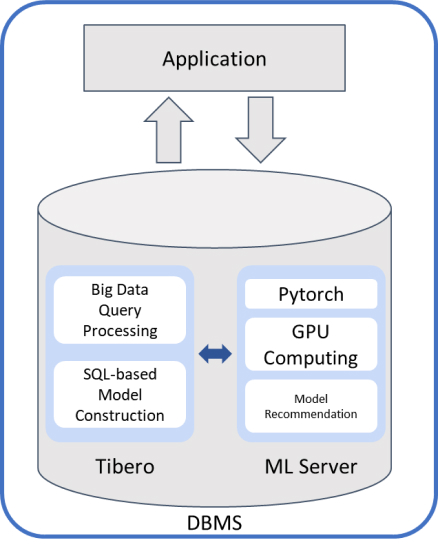
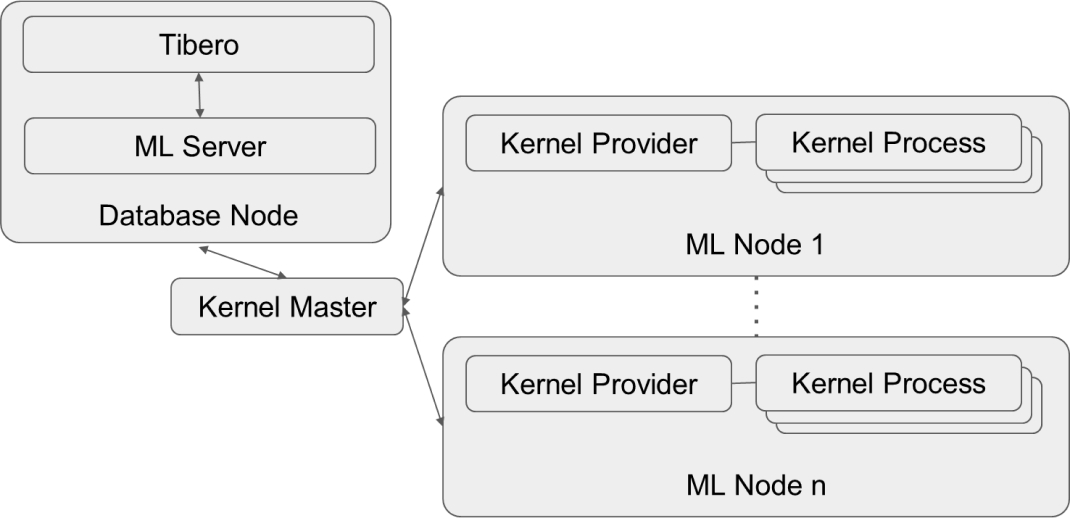
가상 환경 구성
가상 환경 활성화 및 의존성 설치
기본 구동
tip 파일 설정
DBMS_ML system table 생성
DBMS_ML package 생성
Data Table 생성 및 Data 삽입
Training, Test Table 생성
Model Setting Table 생성 및 입력
Train 수행
Predict_data_table, Predict_result_table 생성
Predict 수행
Predict 결과 조회



This project is supported by IITP grant funded by the Korea government(MSIT)(No.2021 - 0 - 00113,
Cloud - based next - generation DBMS technology development for big data analysis and AI processing)


















